Spatial mapping of cell types across the mouse brain (2/3) - cell2location¶
This notebook demonstrates how to use the cell2location model for mapping a single cell reference cell types onto a spatial transcriptomic dataset. Here, we use a 10X single nucleus RNA-sequencing (snRNAseq) and Visium spatial transcriptomic data generated from adjacent tissue sections of the mouse brain (Kleshchevnikov et al., BioRxiv 2020).
The first step of our model (#2 in Fig 1, tutorial 1/3) is to estimate reference cell type signatures from scRNA-seq profiles, for example as obtained using conventional clustering to identify cell types and subpopulations followed by estimation of average cluster gene expression profiles (Suppl. Methods, Section 2, Fig S1). Cell2location implements this estimation step based on Negative Binomial regression, which allows to robustly combine data across technologies and batches (Suppl. Methods, Section 2).
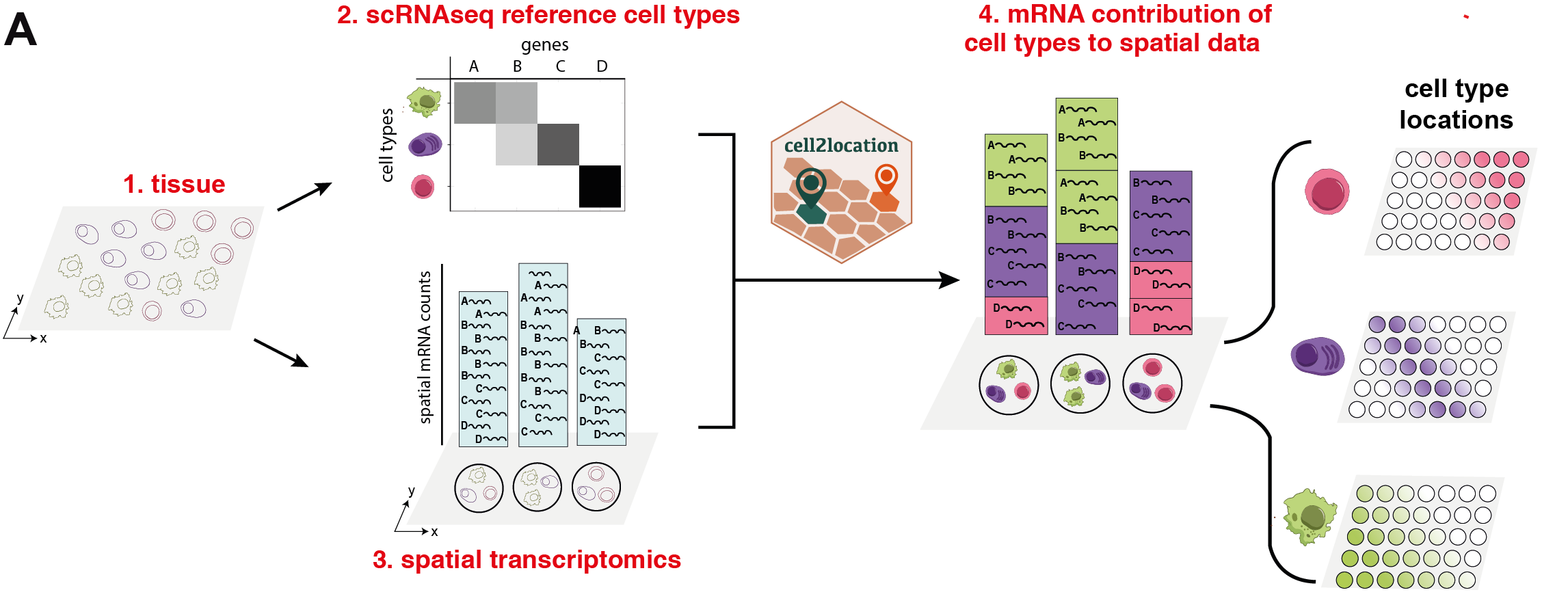
In the second step covered by this notebook (#4 in Fig 1), cell2location decomposes mRNA counts in spatial transcriptomic data using these reference signatures, thereby estimating the relative and absolute abundance of each cell type at each spatial location (Suppl. Methods, Section 1, Fig S1).
Outline¶
The **cell2location** workflow consists of three sections:
Estimating reference expression signatures of cell types (1/3)
Spatially mapping cell types (2/3, this notebook):
Load reference cell type signature from snRNA-seq data and show UMAP of cells
Cell2location model description and analysis pipeline, Evaluating training
Results and downstream analysis (3/3)
Loading packages and setting up GPU¶
First, we need to load the relevant packages and tell cell2location to use the GPU. cell2location is written in pymc3 language for probabilistic modelling that uses a deep learning library called theano for heavy computations. While the package works on both GPU and CPU, using the GPU significantly shortens the computation time for 10X Visium datasets. Using the CPU is more feasible for smaller datasets with fewer spatial locations (e.g. Nanostring WTA technology).
[1]:
import sys
import scanpy as sc
import anndata
import pandas as pd
import numpy as np
import os
import gc
# this line forces theano to use the GPU and should go before importing cell2location
os.environ["THEANO_FLAGS"] = 'device=cuda0,floatX=float32,force_device=True'
# if using the CPU uncomment this:
#os.environ["THEANO_FLAGS"] = 'device=cpu,floatX=float32,openmp=True,force_device=True'
import cell2location
import matplotlib as mpl
from matplotlib import rcParams
import matplotlib.pyplot as plt
import seaborn as sns
# silence scanpy that prints a lot of warnings
import warnings
warnings.filterwarnings('ignore')
/nfs/team283/vk7/software/miniconda3farm5/envs/cellpymc/lib/python3.7/site-packages/theano/gpuarray/dnn.py:184: UserWarning: Your cuDNN version is more recent than Theano. If you encounter problems, try updating Theano or downgrading cuDNN to a version >= v5 and <= v7.
warnings.warn("Your cuDNN version is more recent than "
Using cuDNN version 8201 on context None
Mapped name None to device cuda0: Tesla V100-SXM2-32GB (0000:62:00.0)
Tips on initializing GPU THEANO_FLAGS='force_device=True' forces the package to use GPU. Pay attention to error messages that might indicate theano failed to initalise the GPU. E.g. failure to use cuDNN will lead to significant slowdown.
Above you should see a message similar to this confirming that theano started using the GPU:
/lib/python3.7/site-packages/theano/gpuarray/dnn.py:184: UserWarning: Your cuDNN version is more recent than Theano. If you encounter problems, try updating Theano or downgrading cuDNN to a version >= v5 and <= v7.
warnings.warn("Your cuDNN version is more recent than "
Using cuDNN version 7605 on context None
Mapped name None to device cuda0: Tesla V100-SXM2-32GB (0000:89:00.0)
Do not forget to change device=cuda0 to your available GPU id. Use device=cuda / device=cuda0 if you have just one locally or if you are requesting one GPU via HPC cluster job. You can see availlable GPU by openning a terminal in jupyter and running nvidia-smi.
1. Loading Visium data¶
In this tutorial, we use a paired Visium and snRNAseq reference dataset of the mouse brain (i.e. generated from adjacent tissue sections). There are two biological replicates and several tissue sections from each brain, totalling 5 10X visium samples.
First, we need to download and unzip spatial data, as well as download estimated signatures of reference cell types, from our data portal:
[2]:
# Set paths to data and results used through the document:
sp_data_folder = './data/mouse_brain_visium_wo_cloupe_data/'
results_folder = './results/mouse_brain_snrna/'
regression_model_output = 'RegressionGeneBackgroundCoverageTorch_65covariates_40532cells_12819genes'
reg_path = f'{results_folder}regression_model/{regression_model_output}/'
# Download and unzip spatial data
if os.path.exists('./data') is not True:
os.mkdir('./data')
os.system('cd ./data && wget https://cell2location.cog.sanger.ac.uk/tutorial/mouse_brain_visium_wo_cloupe_data.zip')
os.system('cd ./data && unzip mouse_brain_visium_wo_cloupe_data.zip')
# Download and unzip snRNA-seq data with signatures of reference cell types
# (if the output folder was not created by tutorial 1/3)
if os.path.exists(reg_path) is not True:
os.mkdir('./results')
os.mkdir(f'{results_folder}')
os.mkdir(f'{results_folder}regression_model')
os.mkdir(f'{reg_path}')
os.system(f'cd {reg_path} && wget https://cell2location.cog.sanger.ac.uk/tutorial/mouse_brain_snrna/regression_model/RegressionGeneBackgroundCoverageTorch_65covariates_40532cells_12819genes/sc.h5ad')
Now, let’s read the spatial Visium data from the 10X Space Ranger output and examine several QC plots. Here, we load the our Visium mouse brain experiments (i.e. sections) and corresponding histology images into a single anndata object adata.
[3]:
def read_and_qc(sample_name, path=sp_data_folder + 'rawdata/'):
r""" This function reads the data for one 10X spatial experiment into the anndata object.
It also calculates QC metrics. Modify this function if required by your workflow.
:param sample_name: Name of the sample
:param path: path to data
"""
adata = sc.read_visium(path + str(sample_name),
count_file='filtered_feature_bc_matrix.h5', load_images=True)
adata.obs['sample'] = sample_name
adata.var['SYMBOL'] = adata.var_names
adata.var.rename(columns={'gene_ids': 'ENSEMBL'}, inplace=True)
adata.var_names = adata.var['ENSEMBL']
adata.var.drop(columns='ENSEMBL', inplace=True)
# Calculate QC metrics
from scipy.sparse import csr_matrix
adata.X = adata.X.toarray()
sc.pp.calculate_qc_metrics(adata, inplace=True)
adata.X = csr_matrix(adata.X)
adata.var['mt'] = [gene.startswith('mt-') for gene in adata.var['SYMBOL']]
adata.obs['mt_frac'] = adata[:, adata.var['mt'].tolist()].X.sum(1).A.squeeze()/adata.obs['total_counts']
# add sample name to obs names
adata.obs["sample"] = [str(i) for i in adata.obs['sample']]
adata.obs_names = adata.obs["sample"] \
+ '_' + adata.obs_names
adata.obs.index.name = 'spot_id'
return adata
def select_slide(adata, s, s_col='sample'):
r""" This function selects the data for one slide from the spatial anndata object.
:param adata: Anndata object with multiple spatial experiments
:param s: name of selected experiment
:param s_col: column in adata.obs listing experiment name for each location
"""
slide = adata[adata.obs[s_col].isin([s]), :]
s_keys = list(slide.uns['spatial'].keys())
s_spatial = np.array(s_keys)[[s in k for k in s_keys]][0]
slide.uns['spatial'] = {s_spatial: slide.uns['spatial'][s_spatial]}
return slide
#######################
# Read the list of spatial experiments
sample_data = pd.read_csv(sp_data_folder + 'Visium_mouse.csv')
# Read the data into anndata objects
slides = []
for i in sample_data['sample_name']:
slides.append(read_and_qc(i, path=sp_data_folder + 'rawdata/'))
# Combine anndata objects together
adata = slides[0].concatenate(
slides[1:],
batch_key="sample",
uns_merge="unique",
batch_categories=sample_data['sample_name'],
index_unique=None
)
#######################
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
Note! Mitochondia-encoded genes (gene names start with prefix mt- or MT-) are irrelevant for spatial mapping because their expression represents technical artifacts in the single cell and nucleus data rather than biological abundance of mitochondria. Yet these genes compose 15-40% of mRNA in each location. Hence, to avoid mapping artifacts we strongly recommend removing mitochondrial genes.
[4]:
# mitochondria-encoded (MT) genes should be removed for spatial mapping
adata.obsm['mt'] = adata[:, adata.var['mt'].values].X.toarray()
adata = adata[:, ~adata.var['mt'].values]
Look at QC metrics¶
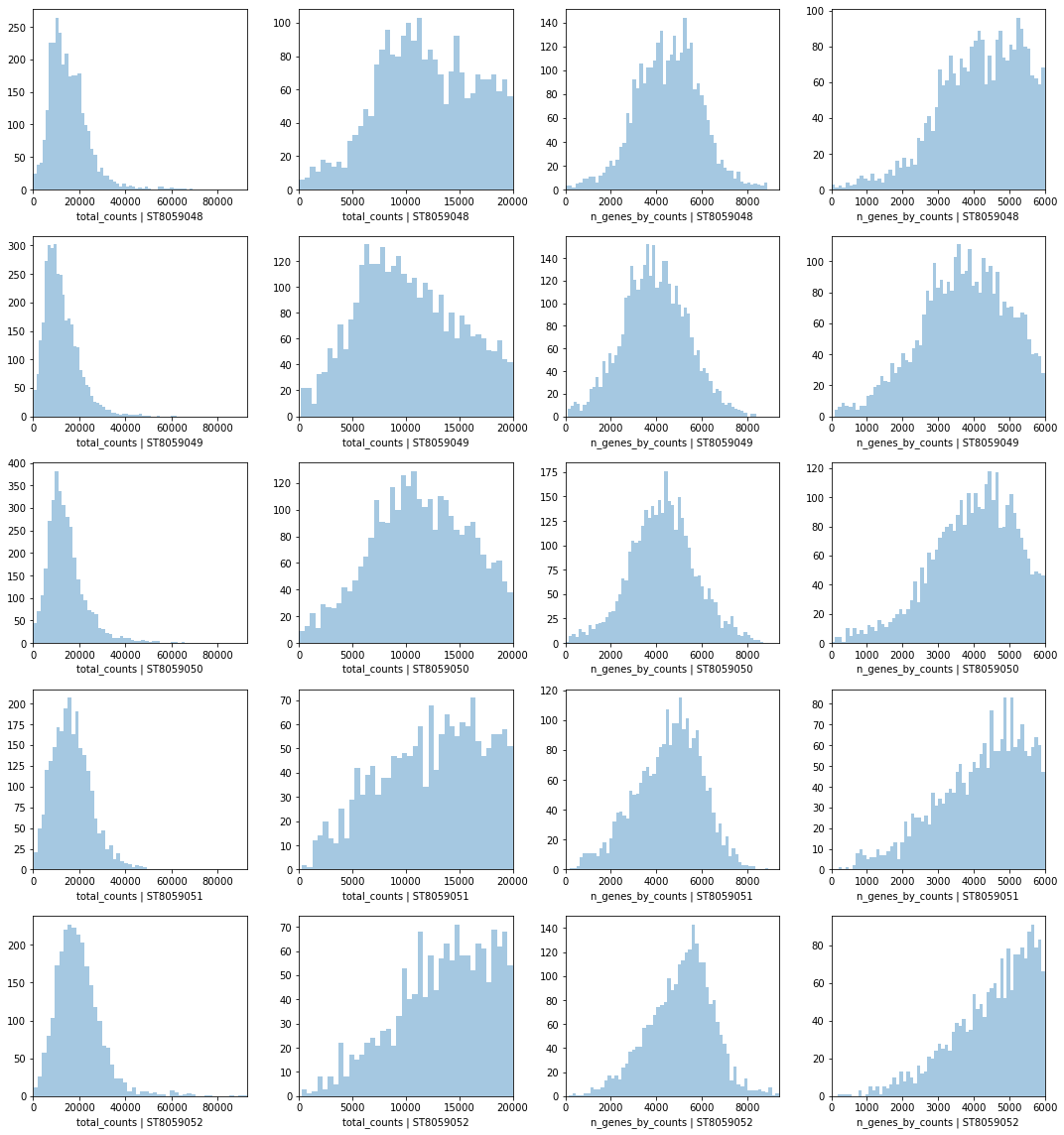
Now let’s look at QC: total number of counts and total number of genes per location across Visium experiments.
[5]:
# PLOT QC FOR EACH SAMPLE
fig, axs = plt.subplots(len(slides), 4, figsize=(15, 4*len(slides)-4))
for i, s in enumerate(adata.obs['sample'].unique()):
#fig.suptitle('Covariates for filtering')
slide = select_slide(adata, s)
sns.distplot(slide.obs['total_counts'],
kde=False, ax = axs[i, 0])
axs[i, 0].set_xlim(0, adata.obs['total_counts'].max())
axs[i, 0].set_xlabel(f'total_counts | {s}')
sns.distplot(slide.obs['total_counts']\
[slide.obs['total_counts']<20000],
kde=False, bins=40, ax = axs[i, 1])
axs[i, 1].set_xlim(0, 20000)
axs[i, 1].set_xlabel(f'total_counts | {s}')
sns.distplot(slide.obs['n_genes_by_counts'],
kde=False, bins=60, ax = axs[i, 2])
axs[i, 2].set_xlim(0, adata.obs['n_genes_by_counts'].max())
axs[i, 2].set_xlabel(f'n_genes_by_counts | {s}')
sns.distplot(slide.obs['n_genes_by_counts']\
[slide.obs['n_genes_by_counts']<6000],
kde=False, bins=60, ax = axs[i, 3])
axs[i, 3].set_xlim(0, 6000)
axs[i, 3].set_xlabel(f'n_genes_by_counts | {s}')
plt.tight_layout()
Trying to set attribute `.uns` of view, copying.
Trying to set attribute `.uns` of view, copying.
Trying to set attribute `.uns` of view, copying.
Trying to set attribute `.uns` of view, copying.
Trying to set attribute `.uns` of view, copying.
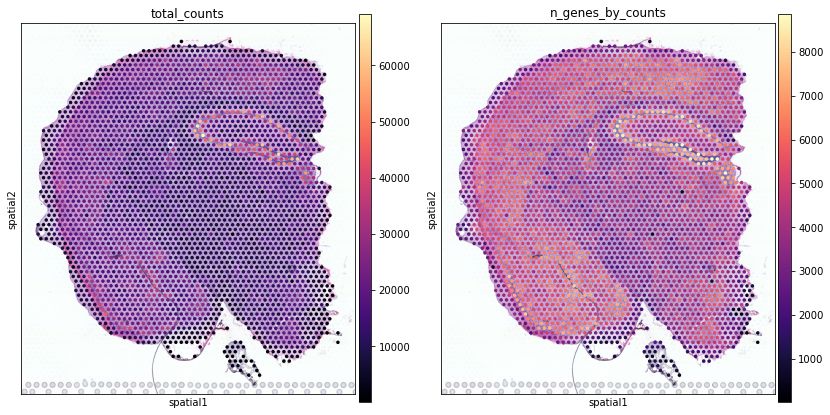
2. Visualise Visium data in spatial 2D and UMAP coordinates¶
Visualising data in spatial coordinates with scanpy¶
Next, we show how to plot these QC values over the histology image using standard scanpy tools
[6]:
slide = select_slide(adata, 'ST8059048')
with mpl.rc_context({'figure.figsize': [6,7],
'axes.facecolor': 'white'}):
sc.pl.spatial(slide, img_key = "hires", cmap='magma',
library_id=list(slide.uns['spatial'].keys())[0],
color=['total_counts', 'n_genes_by_counts'], size=1,
gene_symbols='SYMBOL', show=False, return_fig=True)
Trying to set attribute `.uns` of view, copying.
... storing 'feature_types' as categorical
... storing 'genome' as categorical
... storing 'SYMBOL' as categorical
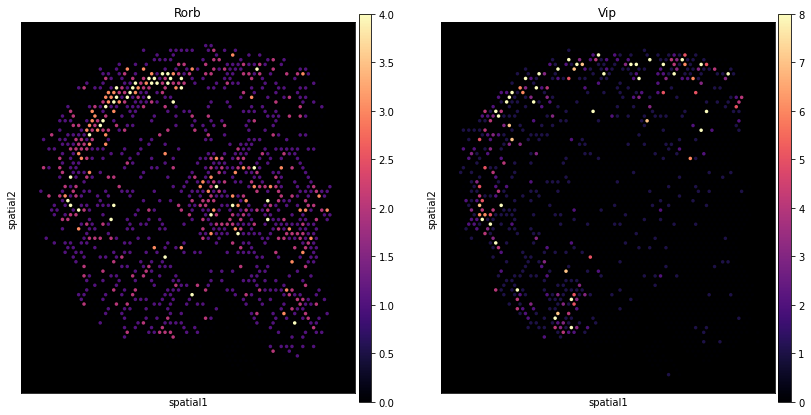
Here we show how to use scanpy to plot the expression of individual genes without the histology image.
[7]:
with mpl.rc_context({'figure.figsize': [6,7],
'axes.facecolor': 'black'}):
sc.pl.spatial(slide,
color=["Rorb", "Vip"], img_key=None, size=1,
vmin=0, cmap='magma', vmax='p99.0',
gene_symbols='SYMBOL'
)
Add counts matrix as adata.raw
[8]:
adata_vis = adata.copy()
adata_vis.raw = adata_vis
Select two Visium sections to speed up the analysis¶
Select two Visium sections, also called experiments / batches, to speed up the analysis, one from each biological replicate.
[9]:
s = ['ST8059048', 'ST8059052']
adata_vis = adata_vis[adata_vis.obs['sample'].isin(s),:]
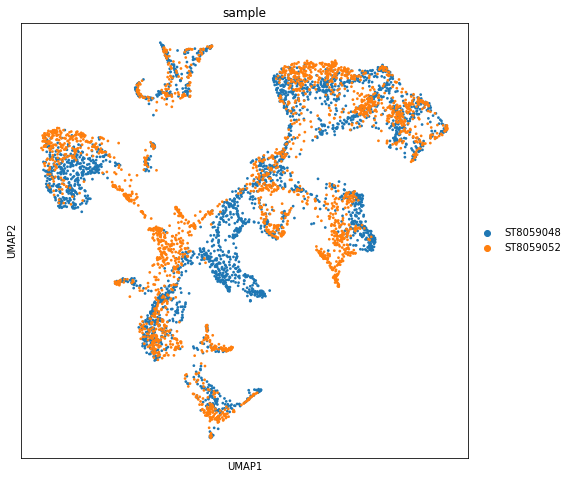
Construct and examine UMAP of locations¶
Now we apply the standard scanpy processing pipeline to the spatial Visium data to show experiment to experiment variability in the data. Importatly, this workflow will show the extent of batch differences in your data (cell2location works on samples jointly, see below).
In this mouse brain dataset, only a few regions should be different between sections because we are using 2 samples from biological replicates sectioned at a slightly different location along the anterior-posterior axis in the mouse brain. We see general alighnment of locations from both experiments and some mismatches, but as you will see in the downstream analysis notebook most of the differences between experiments here come from batch effect, which cell2location can account for.
[10]:
adata_vis_plt = adata_vis.copy()
# Log-transform (log(data + 1))
sc.pp.log1p(adata_vis_plt)
# Find highly variable genes within each sample
adata_vis_plt.var['highly_variable'] = False
for s in adata_vis_plt.obs['sample'].unique():
adata_vis_plt_1 = adata_vis_plt[adata_vis_plt.obs['sample'].isin([s]), :]
sc.pp.highly_variable_genes(adata_vis_plt_1, min_mean=0.0125, max_mean=5, min_disp=0.5, n_top_genes=1000)
hvg_list = list(adata_vis_plt_1.var_names[adata_vis_plt_1.var['highly_variable']])
adata_vis_plt.var.loc[hvg_list, 'highly_variable'] = True
# Scale the data ( (data - mean) / sd )
sc.pp.scale(adata_vis_plt, max_value=10)
# PCA, KNN construction, UMAP
sc.tl.pca(adata_vis_plt, svd_solver='arpack', n_comps=40, use_highly_variable=True)
sc.pp.neighbors(adata_vis_plt, n_neighbors = 20, n_pcs = 40, metric='cosine')
sc.tl.umap(adata_vis_plt, min_dist = 0.3, spread = 1)
with mpl.rc_context({'figure.figsize': [8, 8],
'axes.facecolor': 'white'}):
sc.pl.umap(adata_vis_plt, color=['sample'], size=30,
color_map = 'RdPu', ncols = 1, #legend_loc='on data',
legend_fontsize=10)
Trying to set attribute `.uns` of view, copying.
Trying to set attribute `.uns` of view, copying.
... storing 'feature_types' as categorical
... storing 'genome' as categorical
... storing 'SYMBOL' as categorical
3. Load reference cell type signature from snRNA-seq data and show UMAP of cells¶
Next, we load the pre-processed snRNAseq reference anndata object that contains estimated expression signatures of reference cell types (see notebook 1/3).
[11]:
## snRNAseq reference (raw counts)
adata_snrna_raw = sc.read(f'{reg_path}sc.h5ad')
Export reference expression signatures of cell types:
[12]:
# Column name containing cell type annotations
covariate_col_names = 'annotation_1'
# Extract a pd.DataFrame with signatures from anndata object
inf_aver = adata_snrna_raw.raw.var.copy()
inf_aver = inf_aver.loc[:, [f'means_cov_effect_{covariate_col_names}_{i}' for i in adata_snrna_raw.obs[covariate_col_names].unique()]]
from re import sub
inf_aver.columns = [sub(f'means_cov_effect_{covariate_col_names}_{i}', '', i) for i in adata_snrna_raw.obs[covariate_col_names].unique()]
inf_aver = inf_aver.iloc[:, inf_aver.columns.argsort()]
# normalise by average experiment scaling factor (corrects for sequencing depth)
inf_aver = inf_aver * adata_snrna_raw.uns['regression_mod']['post_sample_means']['sample_scaling'].mean()
Quick look at the cell type composition in our reference data in UMAP coordinates (UMAP representation was generated using a standard scanpy workflow, see notebook 1/3).
[13]:
with mpl.rc_context({'figure.figsize': [10, 10],
'axes.facecolor': 'white'}):
sc.pl.umap(adata_snrna_raw, color=['annotation_1'], size=15,
color_map = 'RdPu', ncols = 1, legend_loc='on data',
legend_fontsize=10)

[14]:
# now we don't need to keep the scRNA-seq data set and a list with slides in memory
del adata_snrna_raw, slides
gc.collect()
[14]:
113332
4. Cell2location model description and analysis pipeline¶
In this section we show how to run cell2location and how to choose hyperparameters.
Cell2location is implemented as an interpretable hierarchical Bayesian model, thereby (1) providing principled means to account for model uncertainty; (2) accounting for linear dependencies in cell type abundances, (3) modelling differences in measurement sensitivity across technologies, and (4) accounting for unexplained/residual variation by employing a flexible count-based error model. Finally, (5) cell2location support joint modelling of multiple experiments / batches.
Brief description of the model¶
For a complete derivation of the cell2location model, please see Suppl. Methods, Section 2. Briefly, cell2location is a Bayesian model, which estimates absolute cell density of cell types by decomposing mRNA counts \(d_{s,g}\) of each gene \(g={1, .., G}\) at locations \(s={1, .., S}\) into a set of predefined reference signatures of cell types \(g_{fg}\). Joint modelling mode works across experiments \(e=\{1,..,E\}\), such as 10X Visium chips (i.e. square capture areas) and Slide-Seq V2 pucks (i.e. beads).
Cell2location models the elements of \(d_{s,g}\) as Negative Binomial distributed, given an unobserved rate \(\mu_{s,g}\) and a gene-specific over-dispersion parameter \(\alpha_{eg}\):
The expression level of genes \(\mu_{s,g}\) in the mRNA count space is modelled as a linear function of expression signatures of reference cell types:
where, \(w_{s,f}\) denotes regression weight of each reference signature \(f\) at location \(s\), which can be interpreted as the number of cells at location \(s\) that express reference signature \(f\); \(m_{g}\) a gene-specific scaling parameter, which adjusts for global differences in sensitivity between technologies; \(l_s\) and \(s_{eg}\) are additive variables that account for gene- and location-specific shift, such as due to contaminating or free-floating RNA.
To account for the similarity of location patterns across cell types, \(w_{s,f}\) is modelled using another layer of decomposition (factorization) using \(r={1, .., R}\) groups of cell types, that can be interpreted as cellular compartments or tissue zones (Suppl. Methods). Unless stated otherwise, \(R\) is set to 50.
Selecting hyper-parameters¶
Note! While the scaling parameter \(m_{g}\) facilitates the integration across technologies, it leads to non-identifiability between \(m_{g}\) and \(w_{s,f}\), unless the informative priors on both variables are used. To address this, we employ informative prior distributions on \(w_{s,f}\) and \(m_{g}\), which are controlled by 4 used-provided hyper-parameters. For guidance on selecting these hyper-parameters see below and Suppl. Methods (Section 1.3).
For the mouse brain we suggest using the following values for 4 used-provided hyper-parameters: 1. \(\hat{N} = 8\), the expected number of cells per location, estimated based on comparison to histology image; 2. \(\hat{A} = 9\), the expected number of cell types per location, assuming that most cells in a given location belong to a different type and that many locations contain cell processes rather than complete cells; 3. \(\hat{Y} = 5\), the expected number of co-located cell type groups per location, assuming that very few cell types have linearly dependent abundance patterns, except for the regional astrocytes and corresponding neurons such that on average about 2 cell types per group are expected \(\hat{A}/\hat{Y}=1.8\); 4. mean and variance that define hyperprior on gene-specific scaling parameter \(m_{g}\), allowing the user to define prior beliefs on the sensitivity of spatial technology compared to the scRNA-seq reference.
Joing modelling of multiple experiments¶
Joint modelling of spatial data sets from multiple experiments provides the several benefits due to sharing information between experiments (such as 10X Visium chips (i.e. square capture areas) and Slide-Seq V2 pucks (i.e. beads)):
Increasing accuracy by improving the ability of the model to distinguish low sensitivity \(m_{g}\) from zero cell abundance \(w_{r,f}\), which is achieved by sharing the change in sensitivity between technologies \(m_{g}\) across experiments. Similarly to common practice in single cell data analysis, this is equivalent to regressing out the effect of technology but not the effect of individual experiment.
Increasing sensitivity by sharing information on cell types with co-varying abundances during decomposition of \(w_{s,f}\) into groups of cell types \(r={1, .., R}\).
Gene selection¶
Note! We recomment to avoid gene selection beyound very permisive approach shown in tutorial 1 on signature estimation, which yields about 10k-16k genes. We observed that selecting genes further generally leads to less robust results especially when data quality is much lower compared to this high-quality mouse brain dataset.
Training cell2location: specifying data input and hyper-parameters¶
Here we show how to train cell2location model to estimate cell abundances in each location. This workflow is wrapped into a single pipeline:
[15]:
sc.settings.set_figure_params(dpi = 100, color_map = 'viridis', dpi_save = 100,
vector_friendly = True, format = 'pdf',
facecolor='white')
r = cell2location.run_cell2location(
# Single cell reference signatures as pd.DataFrame
# (could also be data as anndata object for estimating signatures
# as cluster average expression - `sc_data=adata_snrna_raw`)
sc_data=inf_aver,
# Spatial data as anndata object
sp_data=adata_vis,
# the column in sc_data.obs that gives cluster idenitity of each cell
summ_sc_data_args={'cluster_col': "annotation_1",
},
train_args={'use_raw': True, # By default uses raw slots in both of the input datasets.
'n_iter': 40000, # Increase the number of iterations if needed (see QC below)
# Whe analysing the data that contains multiple experiments,
# cell2location automatically enters the mode which pools information across experiments
'sample_name_col': 'sample'}, # Column in sp_data.obs with experiment ID (see above)
export_args={'path': results_folder, # path where to save results
'run_name_suffix': '' # optinal suffix to modify the name the run
},
model_kwargs={ # Prior on the number of cells, cell types and co-located groups
'cell_number_prior': {
# - N - the expected number of cells per location:
'cells_per_spot': 8, # < - change this
# - A - the expected number of cell types per location (use default):
'factors_per_spot': 7,
# - Y - the expected number of co-located cell type groups per location (use default):
'combs_per_spot': 7
},
# Prior beliefs on the sensitivity of spatial technology:
'gene_level_prior':{
# Prior on the mean
'mean': 1/2,
# Prior on standard deviation,
# a good choice of this value should be at least 2 times lower that the mean
'sd': 1/4
}
}
)
### Summarising single cell clusters ###
### Creating model ### - time 0.03 min
### Analysis name: LocationModelLinearDependentWMultiExperiment_2experiments_59clusters_5563locations_12809genes
### Training model ###
Finished [100%]: Average Loss = 6.0291e+07
[<matplotlib.lines.Line2D object at 0x1541d80b7e50>]
Finished [100%]: Average Loss = 6.0293e+07
[<matplotlib.lines.Line2D object at 0x1541d12c3310>]
### Sampling posterior ### - time 72.95 min
### Saving results ###
... storing 'feature_types' as categorical
... storing 'genome' as categorical
... storing 'SYMBOL' as categorical
... storing 'feature_types' as categorical
... storing 'genome' as categorical
... storing 'SYMBOL' as categorical
### Ploting results ###
[<matplotlib.lines.Line2D object at 0x1541c8951410>]
[<matplotlib.lines.Line2D object at 0x1541c8933290>]
[<matplotlib.lines.Line2D object at 0x1541c925f050>]
[<matplotlib.lines.Line2D object at 0x1541c9248e90>]
### Plotting posterior of W / cell locations ###
### Done ### - time 92.89 min
Cell2location model output¶
The results are saved to:
[16]:
results_folder + r['run_name']
[16]:
'./results/mouse_brain_snrna/LocationModelLinearDependentWMultiExperiment_2experiments_59clusters_5563locations_12809genes'
The absolute abundances of cell types are added to sp_data as columns of sp_data.obs. The estimates of all parameters in the model are exported to sp_data.uns['mod'].
List of output files:¶
sp.h5ad - Anndata object with all results and spatial data.
W_cell_density.csv - absolute abundances of cell types, mean of the posterior distribution.
*(default)* - W_cell_density_q05.csv - absolute abundances of cell types, 5% quantile of the posterior distribution representing confident cell abundance level.
W_mRNA_count.csv - absolute mRNA abundance for each cell types, mean of the posterior distribution.
*(useful for QC, selecting mapped cell types)* - W_mRNA_count_q05.csv - absolute mRNA abundance for each cell types, 5% quantile of the posterior distribution representing confident cell abundance level.
The same 4 estimates are also plotted for each cell type (saved to r['run_name']/plots/scanpy, on black background and overlayed on the histology image paired with each sample (saved with histo_ prefix).
The downstream analysis notebook adds more results and creates the file: - sp_with_clusters.h5ad
When 'save_model': True, the trained model r['mod'] is also saved as a pickle file. You can load the model later and continue training.
[17]:
r = {'run_name': 'LocationModelLinearDependentWMultiExperiment_2experiments_59clusters_5563locations_12809genes'}
Evaluating training¶
Now we need to check if our model has trained successfully by examining a few diagnosic plots.
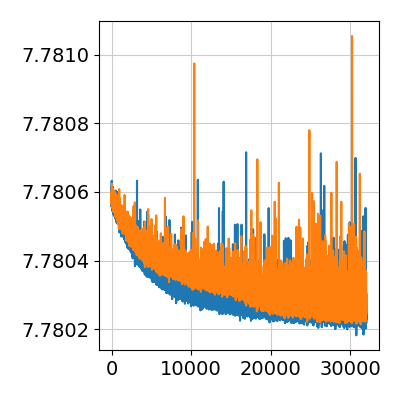
First, we look at the ELBO loss / cost function over training iterations. This plot omits the first 20% of training iterations during which loss changes by many orders of magnitude. Here we see that the model converged by the end of training, some noise in the ELBO loss function is acceptable. If there are large changes during the last few thousands of iterations we recommend increasing the 'n_iter' parameter.
Divergence in ELBO loss between training iterations indicates the problem with training which can be caused by incomplete or insufficiently detailed reference of cell types.
[18]:
from IPython.display import Image
Image(filename=results_folder +r['run_name']+'/plots/training_history_without_first_20perc.png',
width=400)
[18]:
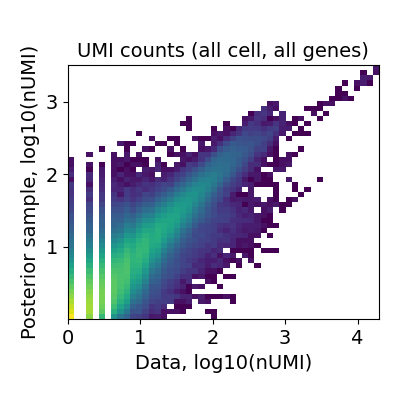
We also need to evaluate the reconstruction accuracy: how well reference cell type signatures explain spatial data by comparing expected value of the model \(\mu_{s,g}\) (Negative Binomial mean) to observed count of each gene across locations. The ideal case is a perfect diagonal 2D histogram plot (across genes and locations).
A very fuzzy diagonal or large deviations of some genes and locations from the diagonal plot indicate that the reference signatures are incomplete. The reference could be missing certain cell types entirely (e.g. FACS-sorting one cell lineage) or clustering could be not sufficiently granular (e.g. mapping 5-10 broad cell types to a complex tissue). Below is an example of good performance:
[19]:
Image(filename=results_folder +r['run_name']+'/plots/data_vs_posterior_mean.png',
width=400)
[19]:
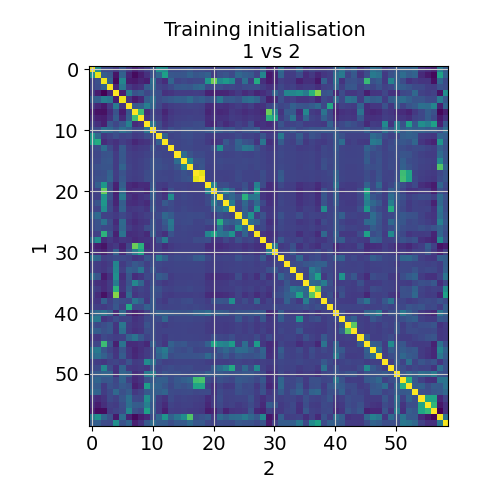
Finally, we need to evaluate robustness of the identified locations by comparing consistency of estimated cell abundances between two independent training restarts (X- and Y-axis). The plot below shows the correlation (color) between cell abundance profiles in 2 training restarts. Some cell types can be correlated, but excessive deviations from diagonal would indicate instability of the solution (we have not seen this so far).
[20]:
Image(filename=results_folder +r['run_name']+'/plots/evaluate_stability.png',
width=400)
[20]:
Modules and their versions used for this analysis
[21]:
import sys
for module in sys.modules:
try:
print(module,sys.modules[module].__version__)
except:
try:
if type(sys.modules[module].version) is str:
print(module,sys.modules[module].version)
else:
print(module,sys.modules[module].version())
except:
try:
print(module,sys.modules[module].VERSION)
except:
pass
sys 3.7.10 | packaged by conda-forge | (default, Feb 19 2021, 16:07:37)
[GCC 9.3.0]
ipykernel 6.2.0
ipykernel._version 6.2.0
json 2.0.9
re 2.2.1
ipython_genutils 0.2.0
ipython_genutils._version 0.2.0
zlib 1.0
platform 1.0.8
jupyter_client 6.1.12
jupyter_client._version 6.1.12
zmq 22.2.1
ctypes 1.1.0
_ctypes 1.1.0
zmq.backend.cython 40304
zmq.backend.cython.constants 40304
zmq.sugar 22.2.1
zmq.sugar.constants 40304
zmq.sugar.version 22.2.1
traitlets 5.0.5
traitlets._version 5.0.5
logging 0.5.1.2
argparse 1.1
jupyter_core 4.7.1
jupyter_core.version 4.7.1
tornado 6.1
colorama 0.4.4
_curses b'2.2'
IPython 7.26.0
IPython.core.release 7.26.0
IPython.core.crashhandler 7.26.0
pygments 2.10.0
pexpect 4.8.0
ptyprocess 0.7.0
decorator 5.0.9
pickleshare 0.7.5
backcall 0.2.0
sqlite3 2.6.0
sqlite3.dbapi2 2.6.0
_sqlite3 2.6.0
prompt_toolkit 3.0.19
wcwidth 0.2.5
jedi 0.18.0
parso 0.8.2
IPython.core.magics.code 7.26.0
urllib.request 3.7
dateutil 2.8.2
dateutil._version 2.8.2
six 1.16.0
decimal 1.70
_decimal 1.70
distutils 3.7.10
scanpy 1.8.1
scanpy._metadata 1.8.1
packaging 21.0
packaging.__about__ 21.0
importlib_metadata 1.7.0
csv 1.0
_csv 1.0
numpy 1.21.2
numpy.core 1.21.2
numpy.version 1.21.2
numpy.core._multiarray_umath 3.1
numpy.lib 1.21.2
numpy.linalg._umath_linalg 0.1.5
scipy 1.7.1
scipy.version 1.7.1
anndata 0.7.6
anndata._metadata 0.7.6
h5py 3.3.0
h5py.version 3.3.0
cached_property 1.5.2
natsort 7.1.1
pandas 1.3.2
pytz 2021.1
numexpr 2.7.3
numexpr.version 2.7.3
sinfo 0.3.1
stdlib_list v0.7.0
numba 0.53.1
yaml 5.4.1
llvmlite 0.36.0
pkg_resources._vendor.appdirs 1.4.3
pkg_resources.extern.appdirs 1.4.3
pkg_resources._vendor.packaging 20.4
pkg_resources._vendor.packaging.__about__ 20.4
pkg_resources.extern.packaging 20.4
pkg_resources._vendor.pyparsing 2.2.1
pkg_resources.extern.pyparsing 2.2.1
numba.misc.appdirs 1.4.1
sklearn 0.24.2
sklearn.base 0.24.2
joblib 1.0.1
joblib.externals.loky 2.9.0
joblib.externals.cloudpickle 1.6.0
scipy._lib.decorator 4.0.5
scipy.linalg._fblas b'$Revision: $'
scipy.linalg._flapack b'$Revision: $'
scipy.linalg._flinalg b'$Revision: $'
scipy.special.specfun b'$Revision: $'
scipy.ndimage 2.0
scipy.optimize.minpack2 b'$Revision: $'
scipy.sparse.linalg.isolve._iterative b'$Revision: $'
scipy.sparse.linalg.eigen.arpack._arpack b'$Revision: $'
scipy.optimize._lbfgsb b'$Revision: $'
scipy.optimize._cobyla b'$Revision: $'
scipy.optimize._slsqp b'$Revision: $'
scipy.optimize._minpack 1.10
scipy.optimize.__nnls b'$Revision: $'
scipy.linalg._interpolative b'$Revision: $'
scipy.integrate._odepack 1.9
scipy.integrate._quadpack 1.13
scipy.integrate._ode $Id$
scipy.integrate.vode b'$Revision: $'
scipy.integrate._dop b'$Revision: $'
scipy.integrate.lsoda b'$Revision: $'
scipy.interpolate._fitpack 1.7
scipy.interpolate.dfitpack b'$Revision: $'
scipy.stats.statlib b'$Revision: $'
scipy.stats.mvn b'$Revision: $'
sklearn.utils._joblib 1.0.1
leidenalg 0.8.7
igraph 0.9.6
texttable 1.6.4
igraph.version 0.9.6
leidenalg.version 0.8.7
louvain 0.7.0
matplotlib 3.4.3
PIL 8.3.1
PIL._version 8.3.1
PIL.Image 8.3.1
defusedxml 0.7.1
xml.etree.ElementTree 1.3.0
cffi 1.14.6
pyparsing 2.4.7
cycler 0.10.0
kiwisolver 1.3.1
tables 3.6.1
umap 0.5.1
_cffi_backend 1.14.6
pycparser 2.20
pycparser.ply 3.9
pycparser.ply.yacc 3.10
pycparser.ply.lex 3.10
pynndescent 0.5.4
theano 1.0.5
theano.version 1.0.5
mkl 2.4.0
scipy._lib._uarray 0.5.1+49.g4c3f1d7.scipy
scipy.signal.spline 0.2
pygpu 0.7.6
mako 1.1.4
markupsafe 2.0.1
theano.gpuarray.dnn 8201
plotnine 0.7.0
patsy 0.5.1
patsy.version 0.5.1
mizani 0.7.3
palettable 3.3.0
mizani.external.husl 4.0.3
statsmodels 0.12.2
statsmodels.api 0.12.2
statsmodels.__init__ 0.12.2
statsmodels.tools.web 0.12.2
pymc3 3.9.3
xarray 0.19.0
xarray.tutorial master
netCDF4 1.5.7
netCDF4._netCDF4 1.5.7
cftime 1.5.0
cftime._cftime 1.5.0
arviz 0.10.0
arviz.data.base 0.10.0
fastprogress 0.2.7
tqdm 4.62.1
tqdm.cli 4.62.1
tqdm.version 4.62.1
tqdm._dist_ver 4.62.1
ipywidgets 7.6.3
ipywidgets._version 7.6.3
torch 1.9.0+cu102
torch.version 1.9.0+cu102
tarfile 0.9.0
torch.cuda.nccl 2708
torch.backends.cudnn 7605
dill 0.3.4
seaborn 0.11.2
seaborn.external.husl 2.1.0
[ ]: